
PARTNERSHIP / Vidispine


About Vidispine
Vidispine, part of Arvato Systems, delivers flexible media management solutions for the media and entertainment industry. The VidiNet platform enables efficient video content handling—on-premises or in the cloud—helping customers turn content into value.
DeepVA product used
Benefits
- Automatic indexing of faces and easy search for people in videos
- Faces are automatically fingerprinted and stored in the DeepVA data model, so they can be used in all subsequent analyses
- Ability to manage and categorize faces using the “Found By Face Analysis” collection sorting feature
Links
Update 09.2025: From ingest to rough cut in seconds.
Together with our partner Vidispine, we’re excited to show how their AI editing assistant helps creators speed up workflows — from ingest to rough cut in no time — so they can focus on what really matters: producing amazing content.
Want to see it live at IBC?
📍 Vidispine – Booth 7.A15
📍 DeepVA – Booth 3.B48D
👉 Take a look at our LinkedIn post with a short trailer
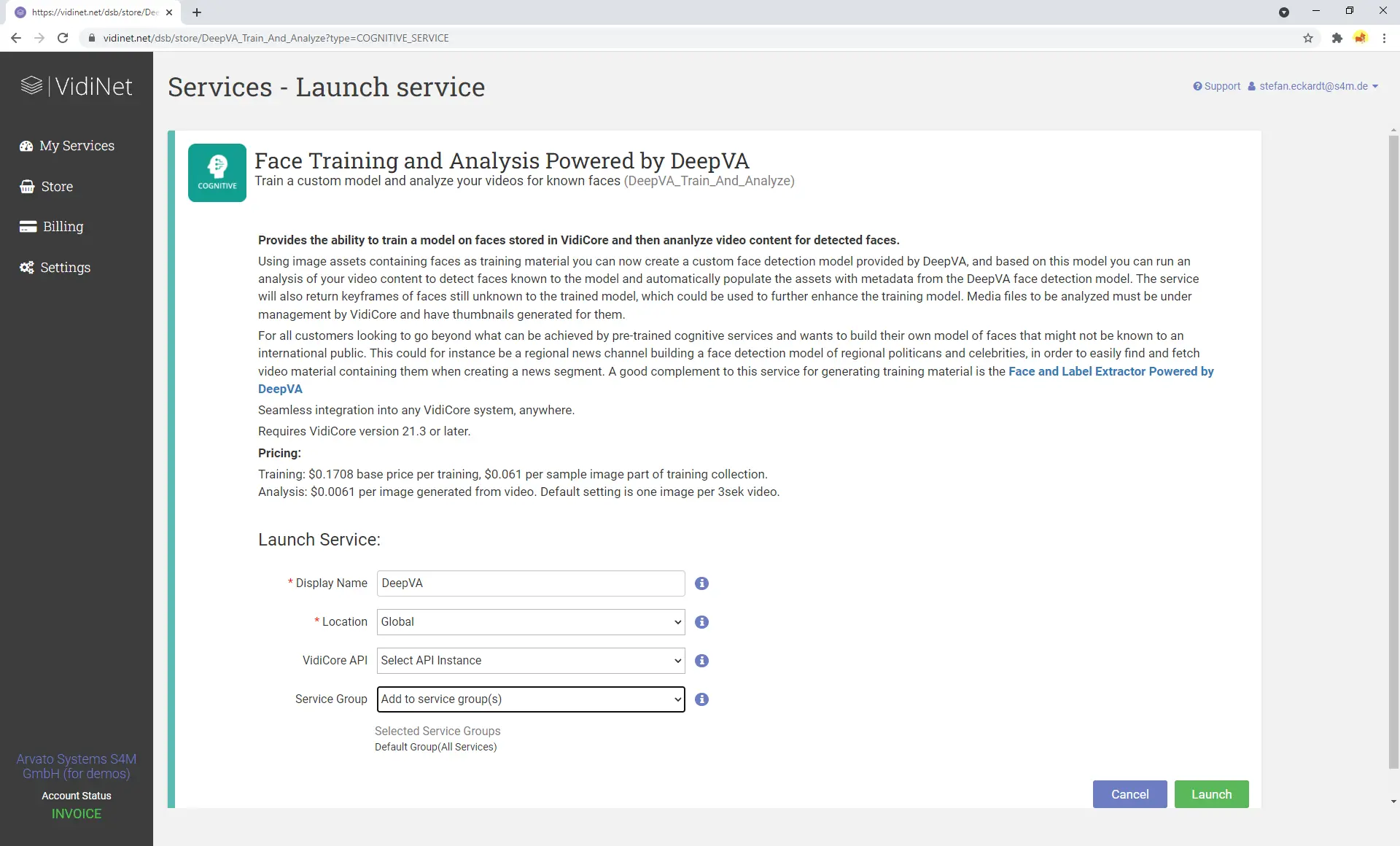
DeepVA Face Training Theme for VidiCore
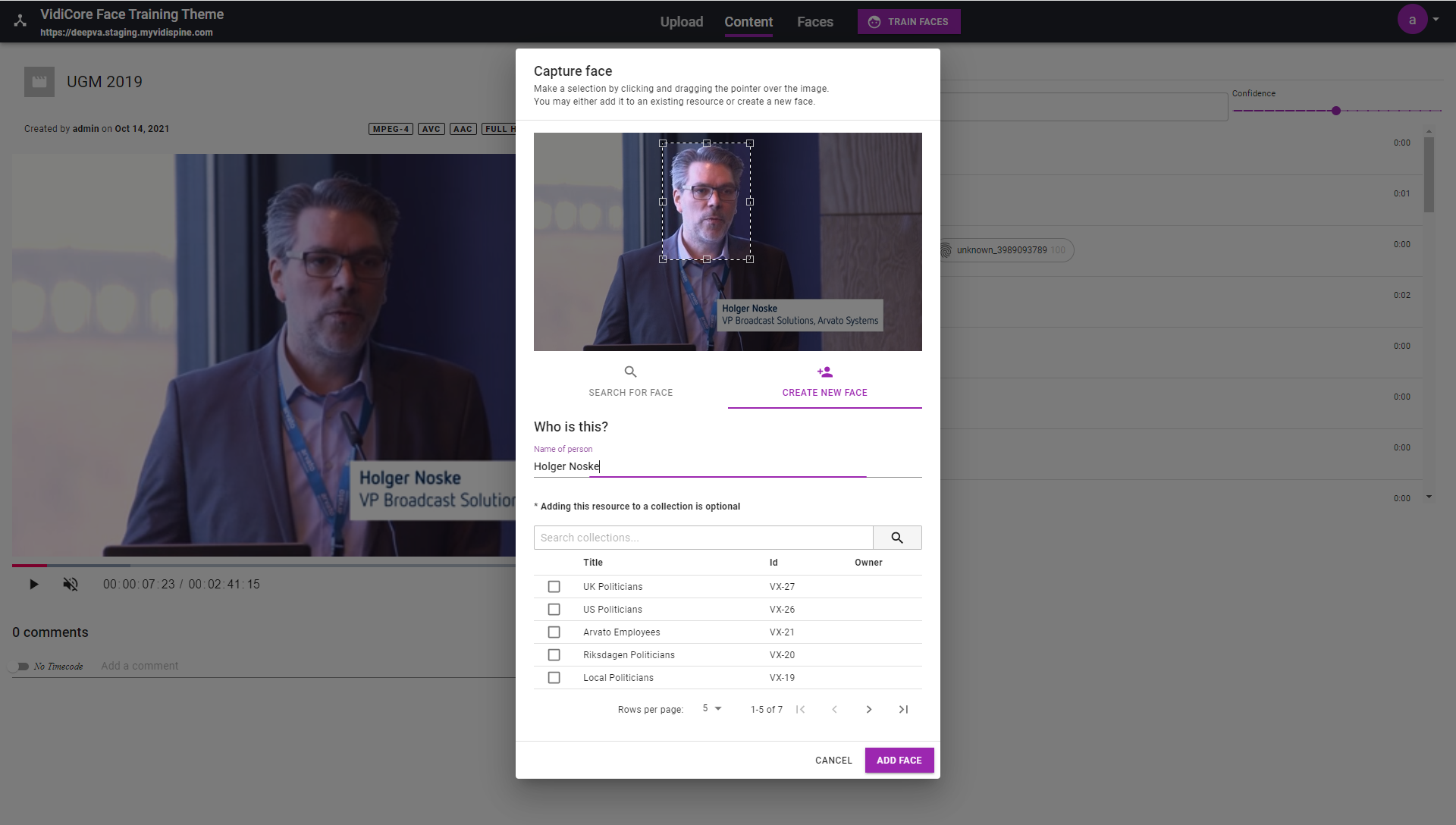
The DeepVA Face Training Theme for VidiCore is an application designed to showcase the capabilities of the DeepVA Face Recognition & Analysis Services within VidiNet. It includes features for analyzing video content using DeepVA AI services in VidiNet, managing and organizing the face data model / database with VidiCore, training the data model with known faces before analysis, manually capturing faces from videos, and more.
VidiCore’s powerful indexing services make it easy to locate and display people and faces by combining AI with time-coded metadata. At its core, the Face Training Theme is a lightweight application that requires minimal configuration. The only prerequisite is a live VidiCore instance with S3 storage, a connected VidiCoder, and one or more linked DeepVA services.
Update 2025: New functionality!
Content Moderation for automated content evaluation, Visual Understanding for prompt-based video analysis, and Highlight Clipping for automatic extraction of key scenes.
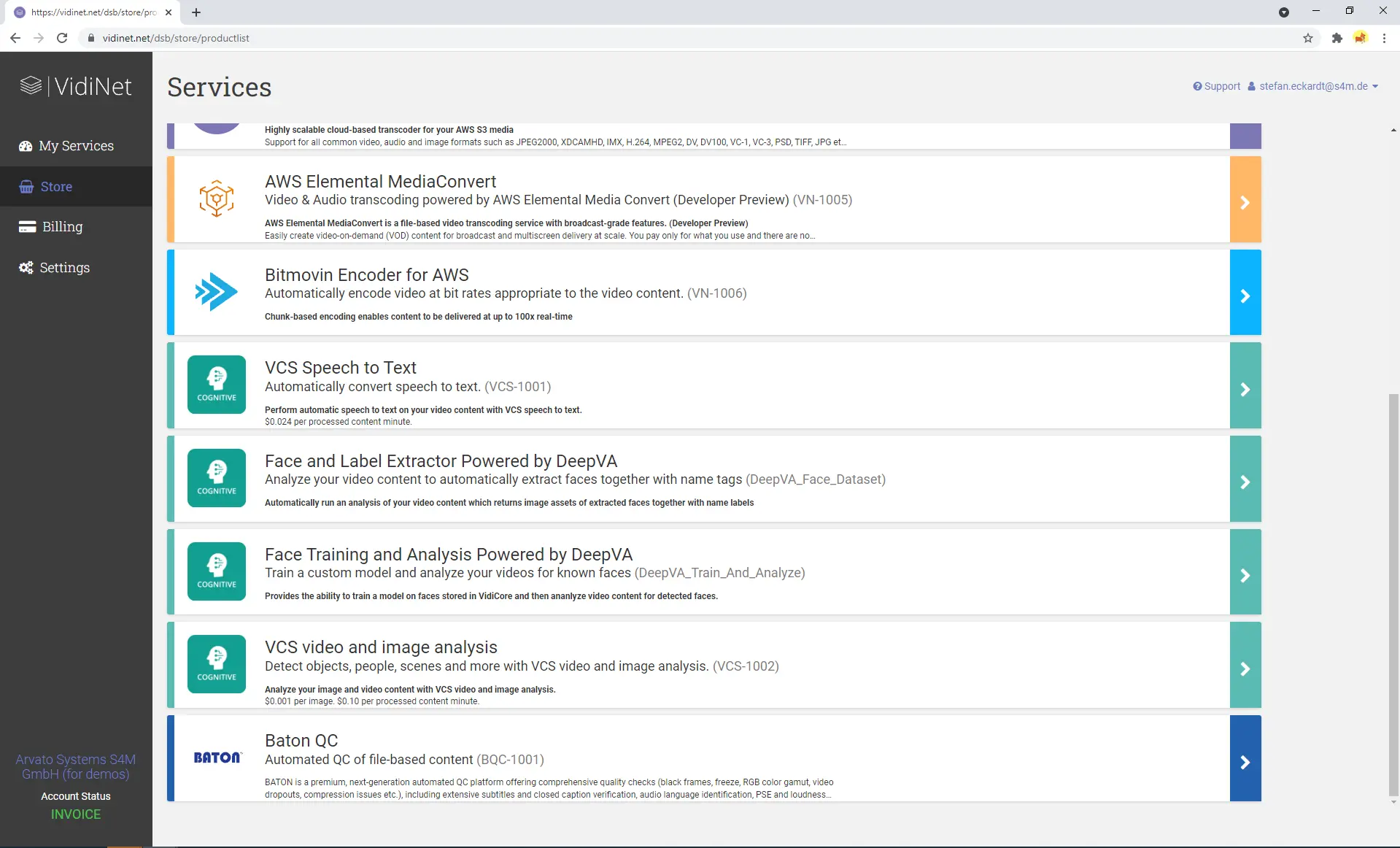
DeepVA Services in VidiNet
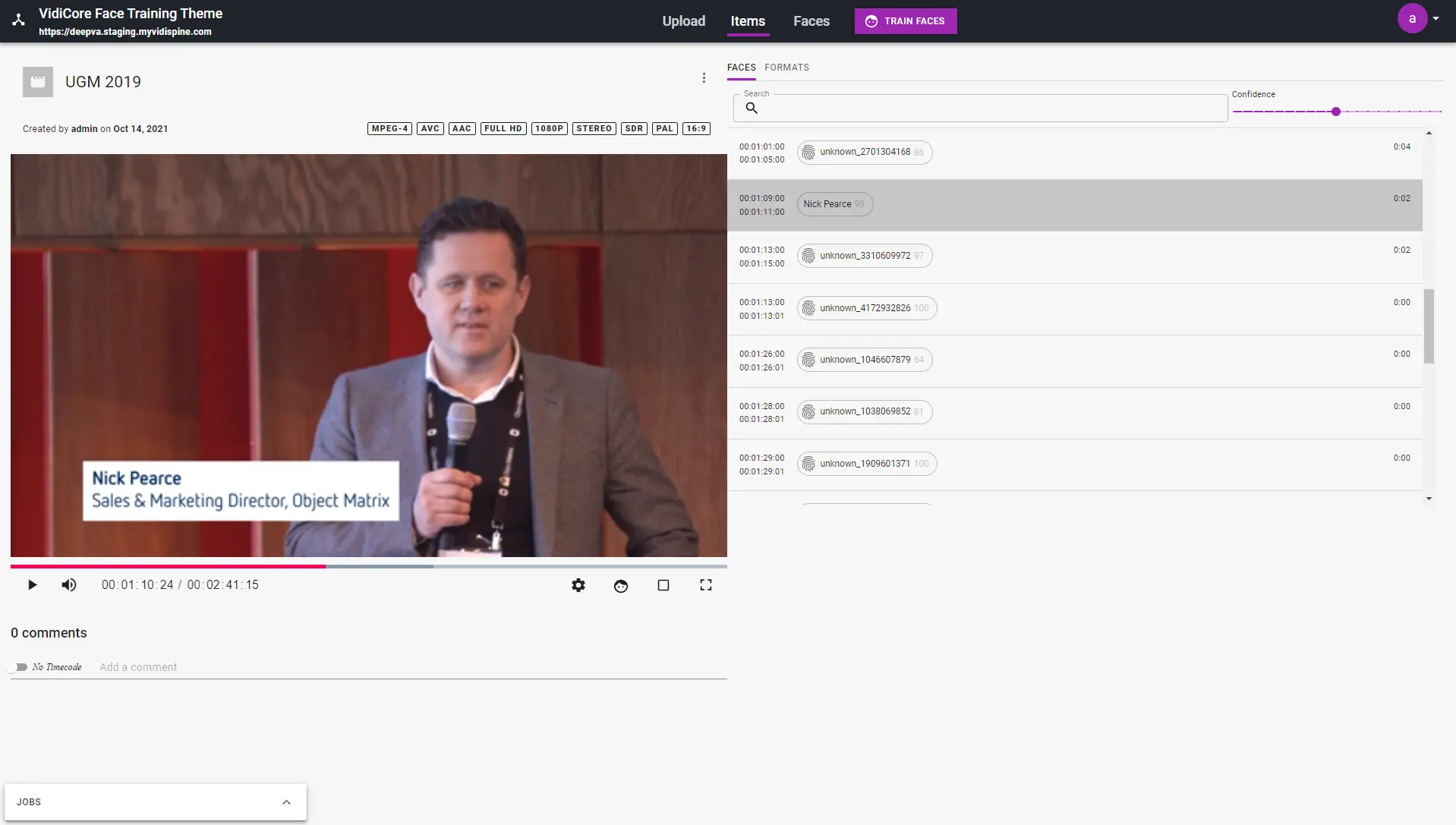
The “Face Training and Analysis Powered by DeepVA” service enables DeepVA’s advanced AI capabilities to analyze video content and detect both known and unknown faces. Each detected face is fingerprinted and compared, with duplicates grouped under a single fingerprint. All findings retain the timecode of where the face was detected, allowing for accurate display of search results in the user interface. This service also allows pre-training of the face model before processing large volumes of content.
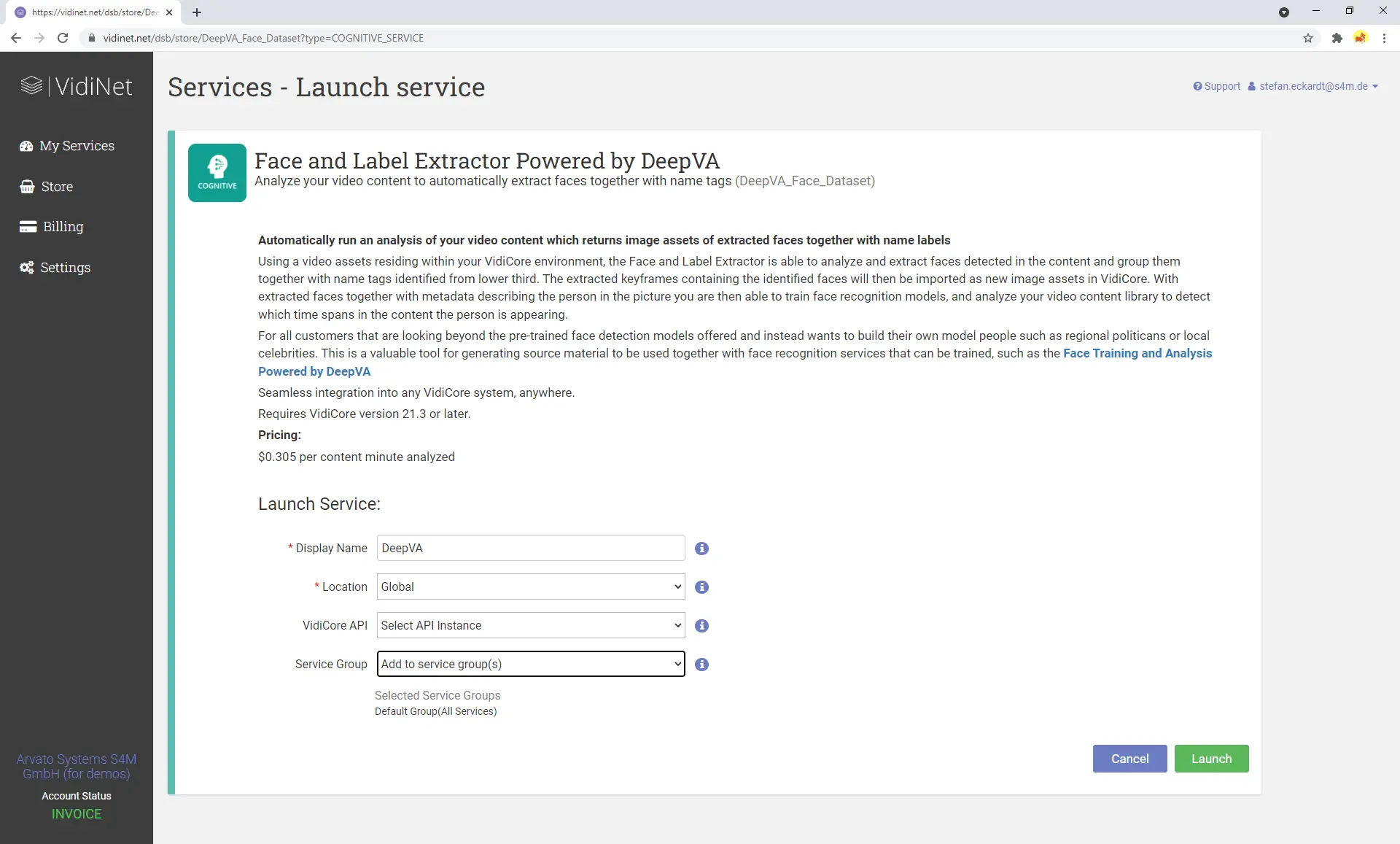
The “Face and Label Extractor Powered by DeepVA” service performs a detailed frame-by-frame analysis to detect faces in video content and match them with textual information found in the lower third area of the screen. Unlike the other service, analysis results from this one do not preserve the timecode of face detection. However, the output can be used to pre-train the face data model for use with the “Face Training and Analysis Powered by DeepVA” service.
The output from the “Face and Label Extractor Powered by DeepVA” is essentially a set of still images of individuals’ faces, accompanied by suggested names based on detected lower third text.
Vidispine Media Portal
Vidispine MediaPortal is a web interface for accessing all media and non-media files managed by Vidispine, and provides functionality for collecting and processing this content within a single search logic and intuitive design. It simplifies your workflows for uploading, housekeeping, editing projects, and distributing content. As a highly integrated part of the Vidispine product portfolio, you can easily customize the application to your specific needs when it comes to production workflows, media supply chains, and collaborative work via a convenient configuration interface.
VidiCore
VidiCore is a Media Management backend service that sees its placement in the base of layer a media supply system. As implied, at the core of your system, its essential role is to handle, and ultimately reduce, the complexity of connecting multiple sources as well as the harvesting and management of media assets and their respective metadata. Coupled together with VidiCoder, VidiCore is able to provide media awareness and proxy generation right out of the box.
Another aspect which grants VidiCore a high degree of flexibility is the fact that it is a REST API service. This enables one to easily develop custom solutions on top of it. VidiCore malleable nature allows one to fit it into various application scenarios: From filling a gap in your existing media workflow, to building sophisticated media management solutions. VidiCore’s architecture is kept simple. It can easily be deployed on an on-prem, or in cloud environment as well as utilizing vendor specify components for easy operation and scalability.
Benefits for the user
Automatic face fingerprinting
Detected faces are automatically stored in the DeepVA data model for subsequent analysis

Efficient search functionality
Easily locate individuals in your media assets

Face management
The software allows you to effectively manage and categorize the faces detected by the DeepVA Face Analysis and Training service
DeepVA functions
DeepVA features integrated into Vidispine
Content moderation
Automate video content moderation with AI. Rate and classify media for violence, nudity, and substance use.
Visual understanding
Analyze video and image content using customizable AI prompts and perform visual question answering.
Audio transcription
Never miss a word. Our Speech to Text function ensures everything spoken is accurately captured in writing.
Face recognition
Detect and identifiy the faces of public figures in a variety of categories such as politics, sports, business, and entertainment.
Landmark recognition
Identify all major sights, architectural structures, and natural monuments across Europe and North America.
Custom AI model training
Train your own AI models for faces, voices, and landmarks — no code needed, no data shared.
Face and speaker dataset creation
Automatically generate entire datasets using facial images, text information (e.g., from lower thirds), and audio eliminating the need for manual labor.
Face index
Expert solutions, tailored to your needs
Ready to unlock the potential of AI for your business? Try DeepVA free of charge for 14 days!


