
PARTNERSCHAFT / Vidispine
Über Vidispine
Vidispine, eine Marke von Arvato Systems, bietet flexible Media-Management-Lösungen für die Medien- und Unterhaltungsbranche. Die VidiNet Plattform ermöglicht eine effiziente Videoinhaltsverarbeitung – lokal oder in der Cloud – und schafft echten Mehrwert.
Verwendetes DeepVA-Produkt
Vorteile
- Automatische Indizierung von Gesichtern und einfache Suche nach Personen in Videos
- Gesichter werden automatisch mit einem Fingerabdruck versehen und im DeepVA-Datenmodell gespeichert, so können sie bei allen nachfolgenden Analysen verwendet werden
- Möglichkeit zur Verwaltung und Kategorisierung von Gesichtern durch die Sortierfunktion der „FoundByFaceAnalysis“-Sammlung
Links
Update 09.2025: Vom Ingest zum Rohschnitt in Sekunden.
Zusammen mit unserem Partner Vidispine zeigen wir, wie ihr KI-gestützter Editing-Assistent Produktionsprozesse deutlich beschleunigt – vom Ingest bis zum Rohschnitt in kürzester Zeit. So bleibt mehr Raum für das, was wirklich zählt: großartige Inhalte.
Treffen Sie uns auf der IBC:
📍 Vidispine – Stand 7.A15
📍 DeepVA – Stand 3.B48D
👉 Schauen Sie sich hier unseren LinkedIn-Post mit Trailer an:
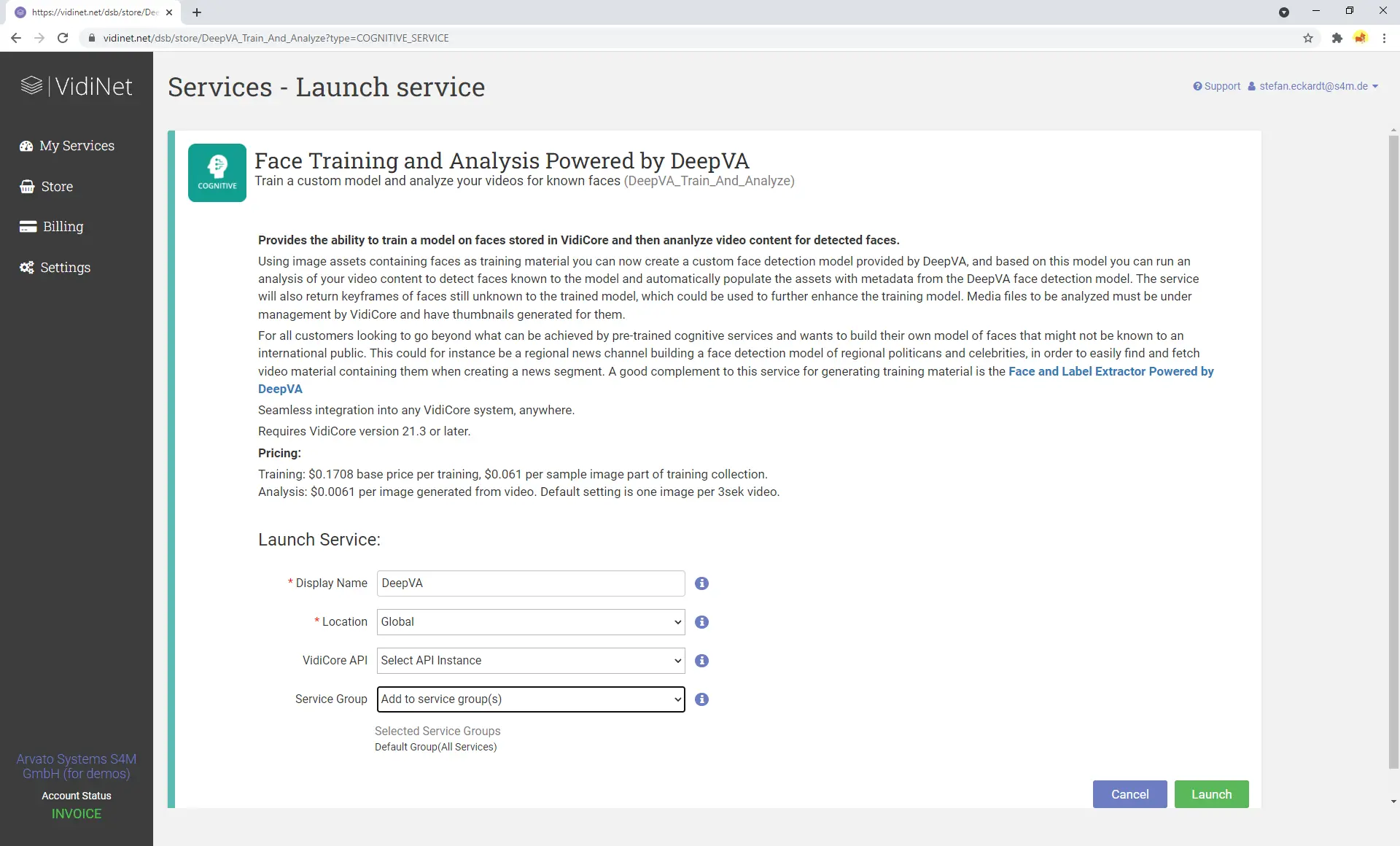
Das DeepVA Face Training Theme for VidiCore
Das DeepVA Face Training Theme für VidiCore ist eine Anwendung zur Visualisierung der Leistungsfähigkeit der DeepVA Gesichtserkennungs- und Analyse-Services in VidiNet. Die Anwendung bietet Funktionen zur Analyse von Videoinhalten mit den DeepVA KI-Diensten in VidiNet, zur Verwaltung und Organisation des Gesichtsdatenmodells bzw. der Datenbank in VidiCore, zum Trainieren des Datenmodells mit bekannten Gesichtern vor der Analyse, zum manuellen Erfassen von Gesichtern in Videos und mehr.
Die leistungsstarken Indexierungsdienste von VidiCore ermöglichen es, Personen und Gesichter mithilfe von KI und zeitcodierten Metadaten einfach zu finden und anzuzeigen. Im Kern ist das Face Training Theme eine schlanke Anwendung, die nur minimale Konfiguration erfordert. Die einzige Voraussetzung ist eine laufende VidiCore-Instanz mit S3-Speicher, ein verbundener VidiCoder sowie ein oder mehrere angebundene DeepVA-Services.
Update 2025: Neue Funktionen!
Content Moderation für automatisierte Inhaltsbewertung, Visual Understanding für prompt-basierte Videoanalyse und Highlight Clipping für die automatische Extraktion wichtiger Szenen.
DeepVA Services in VidiNet
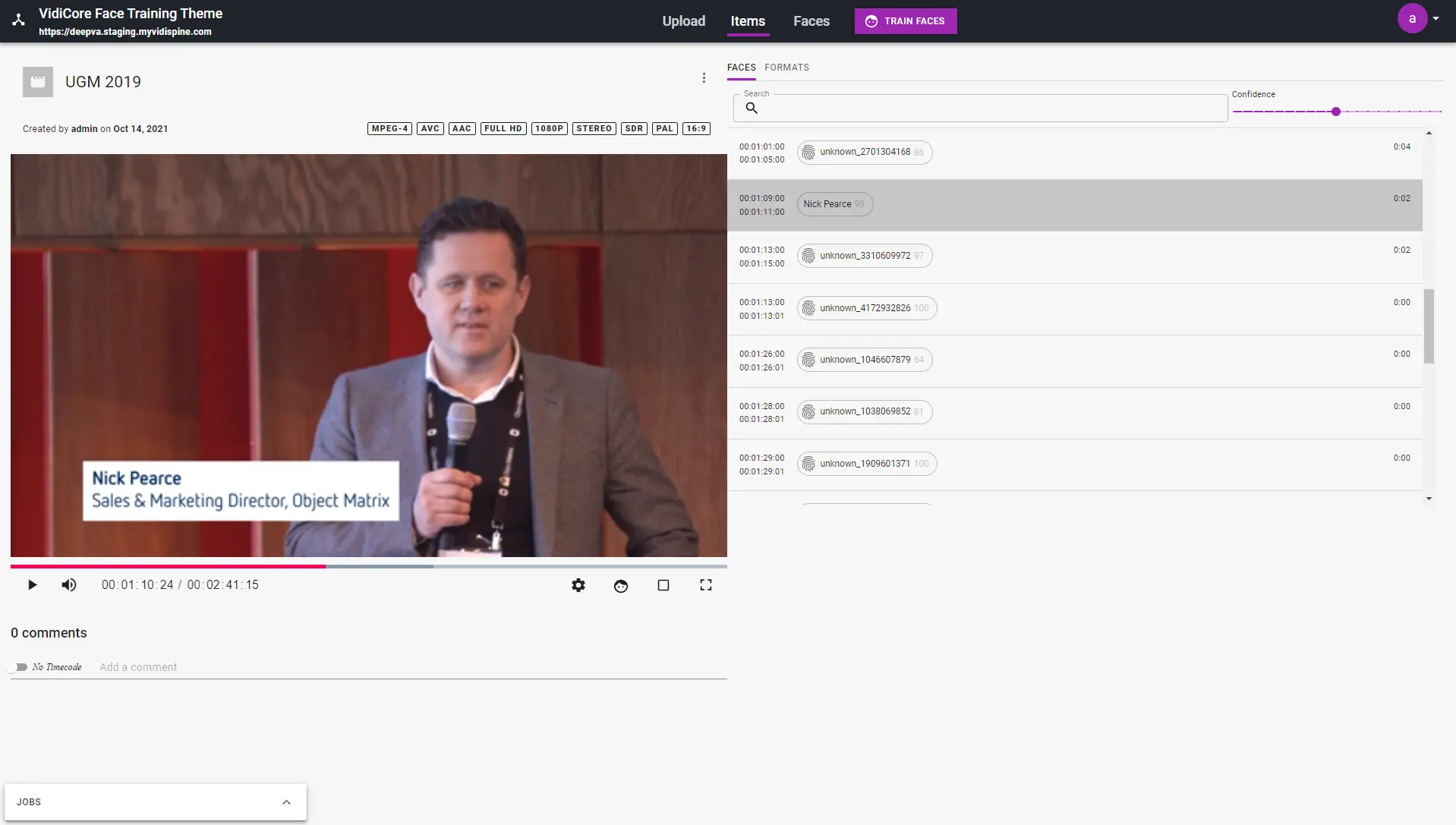
Der „Face Training and Analysis Powered by DeepVA“-Service ermöglicht den Einsatz der leistungsstarken KI-Funktionen von DeepVA zur Analyse von Videoinhalten und zur Erkennung von Gesichtern – sowohl bekannter als auch unbekannter Personen. Jedes erkannte Gesicht wird mit einem Fingerabdruck versehen und mit vorhandenen Daten abgeglichen; Duplikate werden zu einem gemeinsamen Fingerabdruck zusammengeführt. Alle Erkennungen behalten den Zeitcode der jeweiligen Fundstelle, sodass Suchergebnisse korrekt in der Benutzeroberfläche angezeigt werden können. Darüber hinaus bietet dieser Service die Möglichkeit, ein Gesichtsmodell vorab zu trainieren, bevor größere Inhaltsmengen analysiert werden.
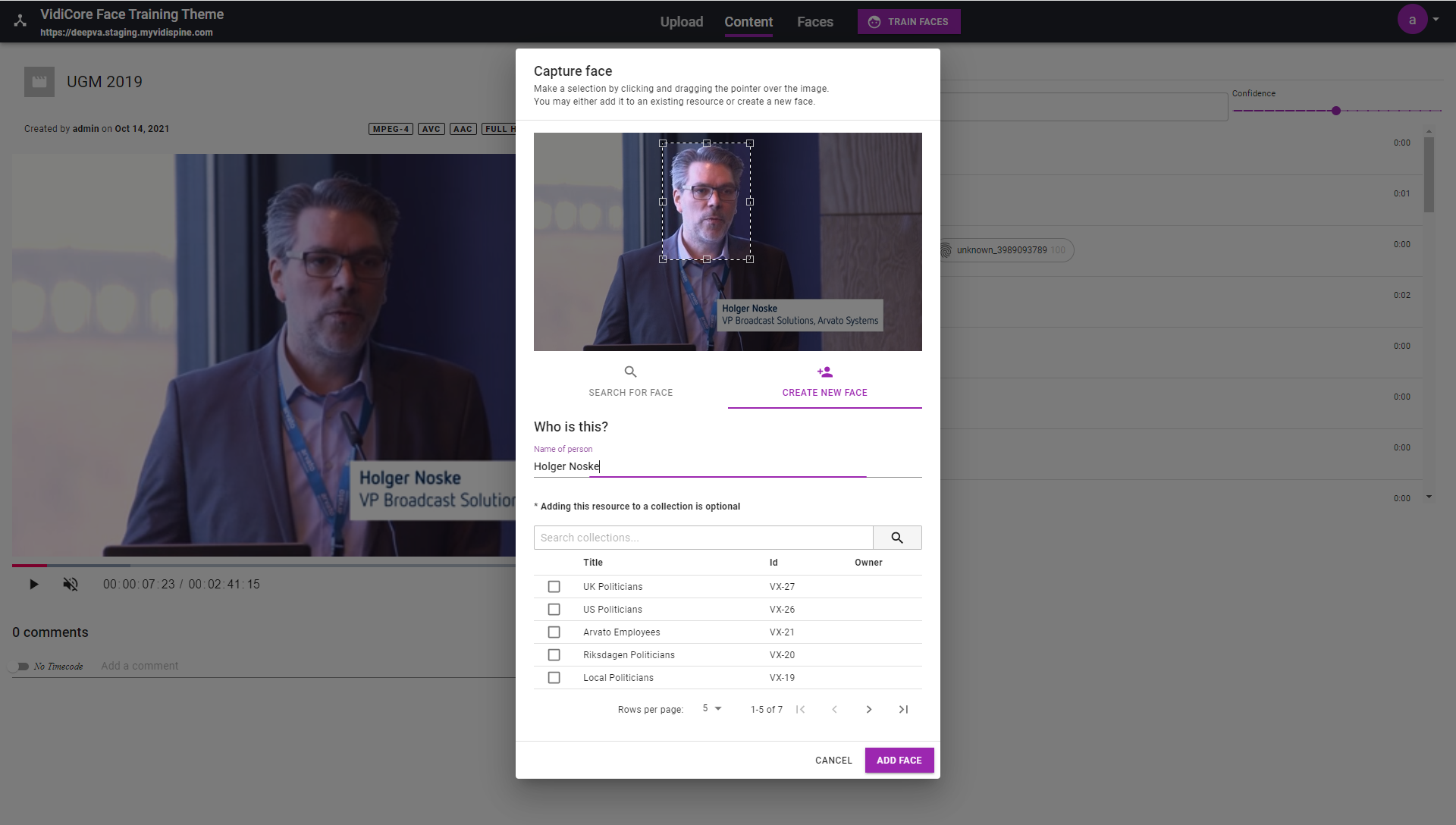
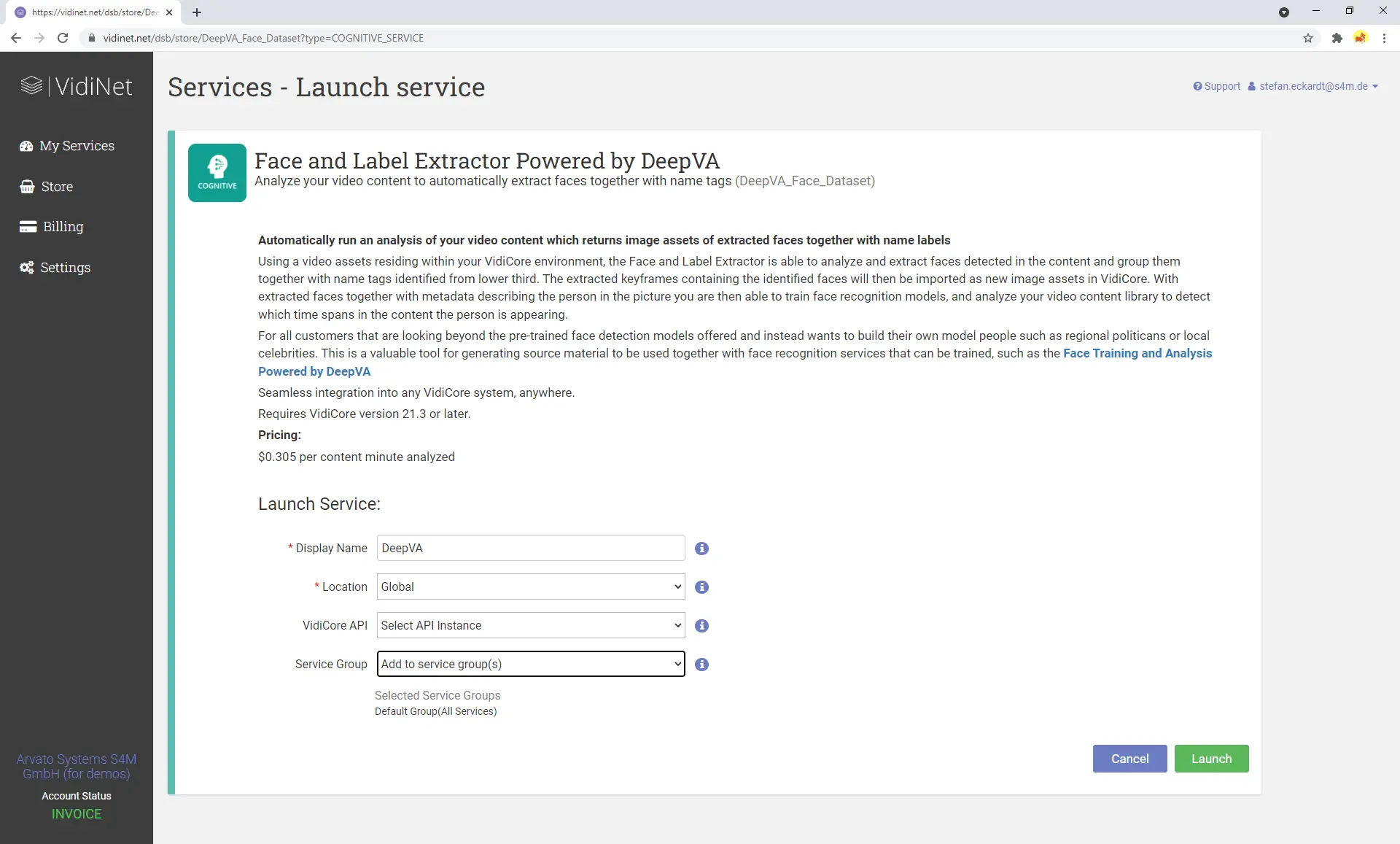
Der „Face and Label Extractor Powered by DeepVA“-Service führt eine gründliche frameweise Analyse von Videos durch, um Gesichter zu erkennen und diese mit Textinformationen im unteren Drittel des Bildes abzugleichen. Die Analyseergebnisse dieses Dienstes enthalten keinen Zeitcode der jeweiligen Gesichtserkennung. Das Ergebnis kann jedoch zum Vortrainieren des Gesichtsdatenmodells für den Einsatz mit dem anderen DeepVA-Service („Face Training and Analysis Powered by DeepVA“) verwendet werden.
Das Ergebnis des „Face and Label Extractor Powered by DeepVA“-Dienstes besteht vereinfacht gesagt aus einer Sammlung von Standbildern mit Gesichtern von Personen sowie einem Namensvorschlag, basierend auf den Textinformationen im unteren Drittel des Videos.
Vidispine Medienportal
Vidispine MediaPortal ist eine Webschnittstelle für den Zugriff auf alle von Vidispine verwalteten Medien- und Nicht-Mediendateien und bietet Funktionen zum Sammeln und Verarbeiten dieser Inhalte innerhalb einer einzigen Suchlogik und eines intuitiven Designs. Es erleichtert Ihre Arbeitsabläufe für Upload, Housekeeping, Bearbeitung von Projekten und Verteilung von Inhalten. Als hochgradig integrierter Teil des Vidispine-Produktportfolios können Sie die Anwendung über eine komfortable Konfigurationsschnittstelle leicht an Ihre speziellen Bedürfnisse anpassen, wenn es um Produktionsworkflows, Medienlieferketten und kollaboratives Arbeiten geht.
VidiCore
VidiCore ist ein Media-Management Backend Service, der als Basis für ein Media Supply System Versorgungssystem sieht. Als Kernstück Ihres Systems besteht seine wesentliche Rolle darin, die Komplexität der Verbindung mehrerer Quellen zu handhaben und letztlich die Komplexität der Verbindung mehrerer Quellen sowie der Erfassung und Verwaltung von Medienbeständen und ihrer jeweiligen Metadaten. In Verbindung mit VidiCoder ist VidiCore in der Lage, Media Awareness und Proxy-Generierung direkt nach dem Auspacken bereitzustellen.
Ein weiterer Aspekt, der VidiCore ein hohes Maß an Flexibilität verleiht, ist die Tatsache, dass es sich um einen REST API Service handelt. Dies ermöglicht die einfache Entwicklung von kundenspezifischen Lösungen auf Basis dieses Dienstes. Die Flexibilität von VidiCore ermöglicht die Anpassung an verschiedene Anwendungsszenarien: von der Schließung einer Lücke in Ihrem bestehenden Medien-Workflow bis hin zum Aufbau komplexer Medienmanagement-Lösungen. Die Architektur von VidiCore ist einfach. Sie kann problemlos in einer On-Premise- oder Cloud-Umgebung eingesetzt werden und nutzt herstellerspezifische Komponenten für einfachen Betrieb und Skalierbarkeit.
Vorteile für den Nutzer
Automatisches Fingerprinting von Gesichtern
Erkannte Gesichter werden automatisch im DeepVA-Datenmodell für spätere Analysen gespeichert

Effiziente Suchfunktionalität
Einfaches Auffinden von Personen in Ihren Medienbeständen

Face Management
Die Software ermöglicht die effektive Verwaltung und Kategorisierung von Gesichtern, die vom DeepVA Face Analysis and Training Service erkannt wurden
DeepVA Funktionen
In Vidispine integrierte DeepVA Funktionen
Content moderation
Automatisieren Sie die Videoinhaltsmoderation mit KI. Bewerten und klassifizieren Sie Medien nach Gewalt, Nacktheit und Substanzgebrauch. Sparen Sie Zeit und verbessern Sie Workflows.
Visual understanding
Analysieren Sie Video- und Bildinhalte mithilfe individuell anpassbarer, KI-gestützter Prompts und beantworten Sie gezielt visuelle Fragestellungen.
Audio Transkription
Keine Silbe verloren! Mit unserer Spracherkennungsfunktion wird jedes Wort präzise in Text umgewandelt.
Face recognition
Erkennen und identifizieren Sie die Gesichter von Persönlichkeiten des öffentlichen Lebens in einer Vielzahl von Kategorien wie Politik, Sport, Wirtschaft und Unterhaltung.
Landmark recognition
Identifizieren Sie alle wichtigen Sehenswürdigkeiten, architektonischen Strukturen und Naturdenkmäler in Europa und Nordamerika.
Individuelles KI-Training
Trainiere deine eigenen KI-Modelle für Gesichter, Stimmen und Merkmale – ganz ohne Programmierkenntnisse und ohne Datenweitergabe.
Erstellung von Gesichts- und Sprecherdatensätzen
Automatische Erstellung ganzer Datensätze aus Gesichtsbildern, Textinformationen (z. B. aus Bauchbinden) und Audio – ganz ohne manuelle Arbeit.
Face index
Individuelle Lösungen, die auf Ihre Bedürfnisse zugeschnitten sind
Sind Sie bereit, das Potenzial von KI für Ihr Unternehmen zu nutzen? Jetzt DeepVA 14 Tage kostenlos testen!



