
Face Dataset Creation
Wenige Bilder des Landmarks reichen, um einen Datensatz zu erstellen und damit genau diese Materialen in Zukunft auffindbar zu machen, in denen der Ort oder die Sehenswürdigkeit enthalten ist.


Deep Indexer
Ähnlichkeits- und Rückwärtssuche
Wie schaffe ich es, ohne eine vortrainierte Gesichtserkennung, Personen zu identifizieren und im Nachgang zu labeln?

Deep Model Customizer
Identifikation eigener Sprecher:Innen
Wie kann ich neue Sprecher:innen in meinem Bestand zukünftig erkennen?

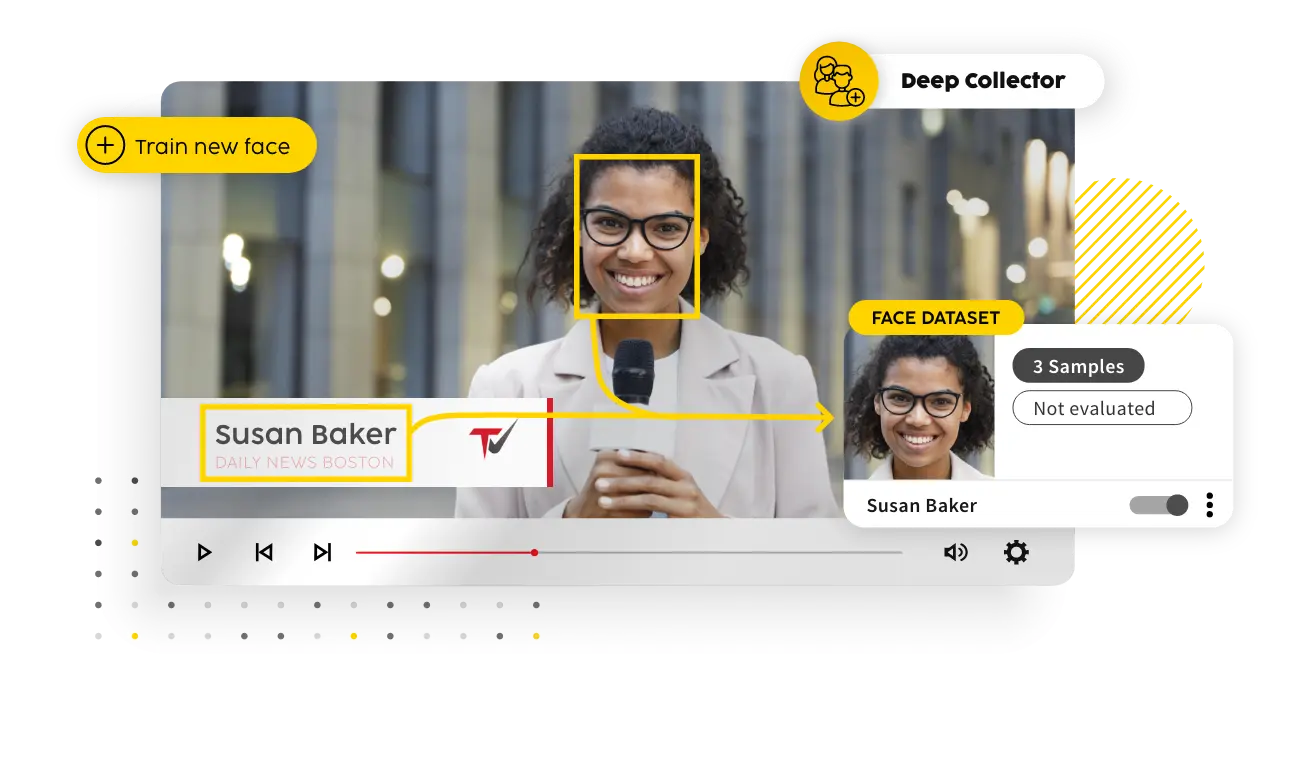
Deep Collector
Automatisch Trainingsdaten aufbauen
Wie kann ich aus meinem Footage automatisiert Trainingsdaten gewinnen?



