

Ein praktisches Beispiel aus dem redaktionellen Umfeld
Ich schreibe eine aktuelle Story über eine neue Recherche zu einem Treffen mehrerer Personen in Potsdam, die zuvor vielleicht nicht im gegenseitigen Kontext standen. Der Knowledge Graph kann, gefüttert aus einer Datenbank, binnen Sekunden alle Verlinkungen zwischen den beiden Personen heraussuchen und so vielleicht Recherche Ansätze für eine Mehrdimensionalität der Story liefern. Vielleicht waren die Personen in der gleichen Hochschule eingeschrieben oder trafen sie sich bei einer anderen Gelegenheit zuvor bereits?
Wissen, welches man als Redakteurin anlernen muss und wofür man für einen Wissenstransfer in der Redaktion einen großen Lernaufwand betreiben muss, kann ein Knowledge Graph in kürzester Zeit bereitstellen.
Es besteht die Gefahr, dass einzelne Verbindungen vielleicht unentdeckt bleiben oder vergessen werden. Der Knowledge Graph erleichtert diesen Transfer, er kann das Wissen um Objekte, Personen, Entitäten einfach transferierbar machen und dies nicht nur für den Menschen.
Große Sprachmodelle (LLM) wie ChatGPT oder Bard liefern auch falsche Informationen.
Sie können zwar mit Sprache und Kontext umgehen, aber die zugrunde liegenden Informationen sind falsch gelernt oder Fakten werden vom LLM frei erfunden. In einem Umfeld, in dem wir von genauen Informationen leben und diese höchste Priorität haben, brauchen wir Verlässlichkeit. Und genau das bietet die Kombination aus einem LLM, der seine Informationen auf einem Wissensgraphen basiert.
Während das Training von LLM extrem viele Texte als Trainingsmaterial benötigt, um überhaupt ein Sprachverständnis zu schaffen, kann der Knowledge Graph genutzt werden, um die Zusammenhänge verschiedener Informationen und die verifizierten Fakten zu lernen, frei von trainierten Unschärfen oder Fehlern.

KNOWLEDGE GRAPH
Knowledge Graph verbindet Wissen, indem er Informationen in Form von Punkten (Entitäten wie Objekte oder Personen) darstellt und diese durch Linien (Beziehungen) verknüpft. Die Punkte repräsentieren einzelne Elemente des Wissens, während die Linien die Beziehungen zwischen ihnen aufzeigen.Doch das ist erst der Anfang: Die Aufbereitung in einem Knowledge Graph bietet weitere Analysemöglichkeiten.
Durch maschinelles Lernen werden weitere Zusammenhänge sichtbar, die der menschlichen Analyse nur schwer zugänglich sind. Zum Beispiel: “Welche Schauspielerinnen unter 1,60 cm haben einen Oscar gewonnen?” Eine Recherche, die ohne Datenbank aufwendiger wäre, dank Graph aber nur wenige Sekunden dauert.
Die Kombination von Wissensgraphen und LLM ermöglicht die Erstellung von spezialisierten LLMs, die nicht nur Sprache beherrschen, sondern auch präzise Informationen in jedem Fachgebiet generieren können – unverzichtbar in zukunftssicheren Unternehmen oder Redaktionen.
Diese Verlässlichkeit wird vor dem Hintergrund kommender regulatorischer Anforderungen wie dem „Artificial Intelligence Act“ der EU besonders wichtig. Transparente und nachvollziehbare LLMs auf Basis von Wissensgraphen sind besser in der Lage, die vorgeschriebenen Regeln zu erfüllen, da sie aufgrund ihrer kontextbezogenen und verifizierten Daten vertrauenswürdiger sind und 100 % nachverfolgbar.
Wie kann so ein Knowledge Graph in journalistische Prozesse Einzug finden – dazu ein Use Case mit CGI’s Open Media.
CGI OpenMedia trifft DeepVA
Das CGI OpenMedia Newsroom Computer System (NRCS) fungiert als kollaborative Plattform für Journalisten, die benötigte Information, Funktionen und Transparenz bereitstellt, um die Herausforderungen der täglichen Nachrichtenproduktion zu bewältigen. Es gewährleistet Höchstgeschwindigkeit und Skalierbarkeit für journalistische Arbeitsabläufe in der Rundfunknachrichtenproduktion, von Drahtsuche über Skripting bis zur Playout-Steuerung.
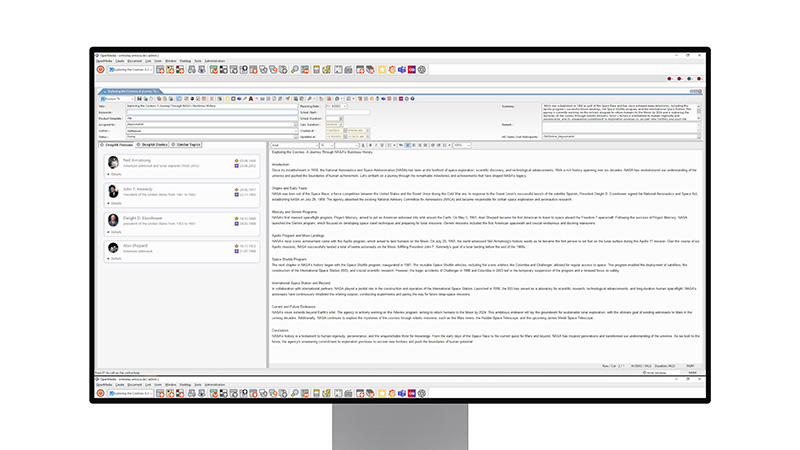
Die Integration von DeepVA in OpenMedia ermöglicht die nahtlose Nutzung intelligenter Funktionen von DeepVA, ohne dass mehrere Anwendungen verwaltet werden müssen. Journalisten erhalten schnell und einfach relevante Informationen zur Unterstützung, Verbesserung und Beschleunigung ihrer täglichen Recherchen. DeepVA identifiziert Personen im Fließtext einer OpenMedia-Story und zeigt sie zusammen mit interessanten Personendaten an, wie kurze Beschreibungen, Geburts- und mögliche Sterbedaten. Zusätzlich werden ähnliche OpenMedia-Stories vorgeschlagen und in der aktuellen Story mit wichtigen Details aufgelistet, wobei der Nutzer automatisch auf alle Details zugreifen kann.






