

KI findet immer mehr Anwendung in unserem Alltag, jedoch weniger als 6 % der Unternehmen in der Medien- und Unterhaltungsbranche nutzen KI in Form von Computer Vision, Voice Recognition oder Natural Language Processing.
Oftmals bietet das aktuelle KI-Angebot nicht den erhofften Mehrwert. Somit ist es wichtig Inhalte in visuellen Medientypen wie Bildern, Videos oder Livestreams zu erkennen, die nicht Teil einer vortrainierten KI sind, sondern den jeweiligen Anforderungen der Firma entsprechen. Eine ständige Anpassung der KI-Modelle ist erforderlich, um den Bedingungen in Medienunternehmen gerecht zu werden.
Um ohne Anpassungen KI-Modelle zu trainieren, müssen dem Nutzer die erforderlichen „Werkzeuge“ bereits im System oder der Applikation intuitiv und transparent zur Verfügung gestellt werden, damit Unternehmen bzw. deren Nutzer die Möglichkeiten haben vorgefertigte KI-Modelle präzise und unkompliziert an ihre Ansprüche anzupassen.
Vortrainierte KI-Modelle
Vortrainierte Modelle, wie wir sie von großen Bilderkennungsdienstleistern kennen, liefern nur den Erkennungsumfang zurück, der dem KI Model über Trainingsdaten antrainiert wurde. Eine Klassifizierung von allgemeinen Bildinhalten kann schnell implementiert werden, medien-und unternehmensspezifische Use Cases können aber nicht vollumfänglich abgedeckt werden. Unternehmen suchen nach Lösungen, die eine Anpassung oder Individualisierung von KI-Modellen ermöglicht und dabei eine hohe Datensicherheit gewährleistet.
Das bedeutet, dass Personen, Objekte oder Landmarks in Bildern und Videos erkannt werden sollen, die nicht Teil eines vortrainierten Models sind. Somit ist die Erkennungsleistung von Inhalten aus Mediendaten mit vortrainierten Modellen sehr begrenzt.
Individuelle KI-Modelle
Der Aufbau eigener KI-Modelle dauerte bisher lange und war sehr komplex. Komplexe Algorithmen werden implementiert und mit großen Trainingsdatenbanken gefüttert. Diese Daten müssen erhoben, strukturiert verwaltet, stetig aktuell gehalten und genau beschrieben werden. Bevor daraus KI-Modelle entstehen und diese einen produktiven Einsatz finden können, müssen sie ausgiebig mit unabhängigen Testdaten auf ihre Leistungsfähigkeit validiert werden. Für Medienhäuser scheint diese Herausforderung bisher nur schwer zu bewältigen zu sein. Die Mission von DeepVA ist es, jedem Unternehmen das Potential von KI zugänglich zu machen, ohne Vorwissen erforderlich zu machen.
KI kann einfach in bestehende Systeme integriert und intuitiv genutzt werden, um so alltägliche Workflows in der Arbeit mit Mediendaten zu optimieren. Dazu gehören das Management von Daten, der Aufbau eigener Trainingsdaten und die Erkennung Analyse von eigenen Inhalten.
Partnerschaft zwischen Vidispine und DeepVA
Auf dem KI – Panel der FKTG auf der Hamburg Open 2020 kam DeepVA das erste Mal mit Arvato Systems ins Gespräch. Ein Folgetermin entpuppte sich als Glücksgriff insofern, dass beide Parteien die Idee fasziniert, Medienworkflows maximal durch KI zu automatisieren. Das Vidispine Team und DeepVA stellten sich gemeinsam die zentrale Frage, wie die richtigen KI-Werkzeuge direkt in die gewohnte Umgebung der Nutzer gebracht werden könnte. Der Nutzer soll außerdem die Möglichkeit haben, die Erkennung von Inhalten seiner Mediendaten, die Erstellung eigener KI-Modelle und die Qualitätssicherung seiner Trainingsdaten eigenhändig überwachen und steuern zu können.
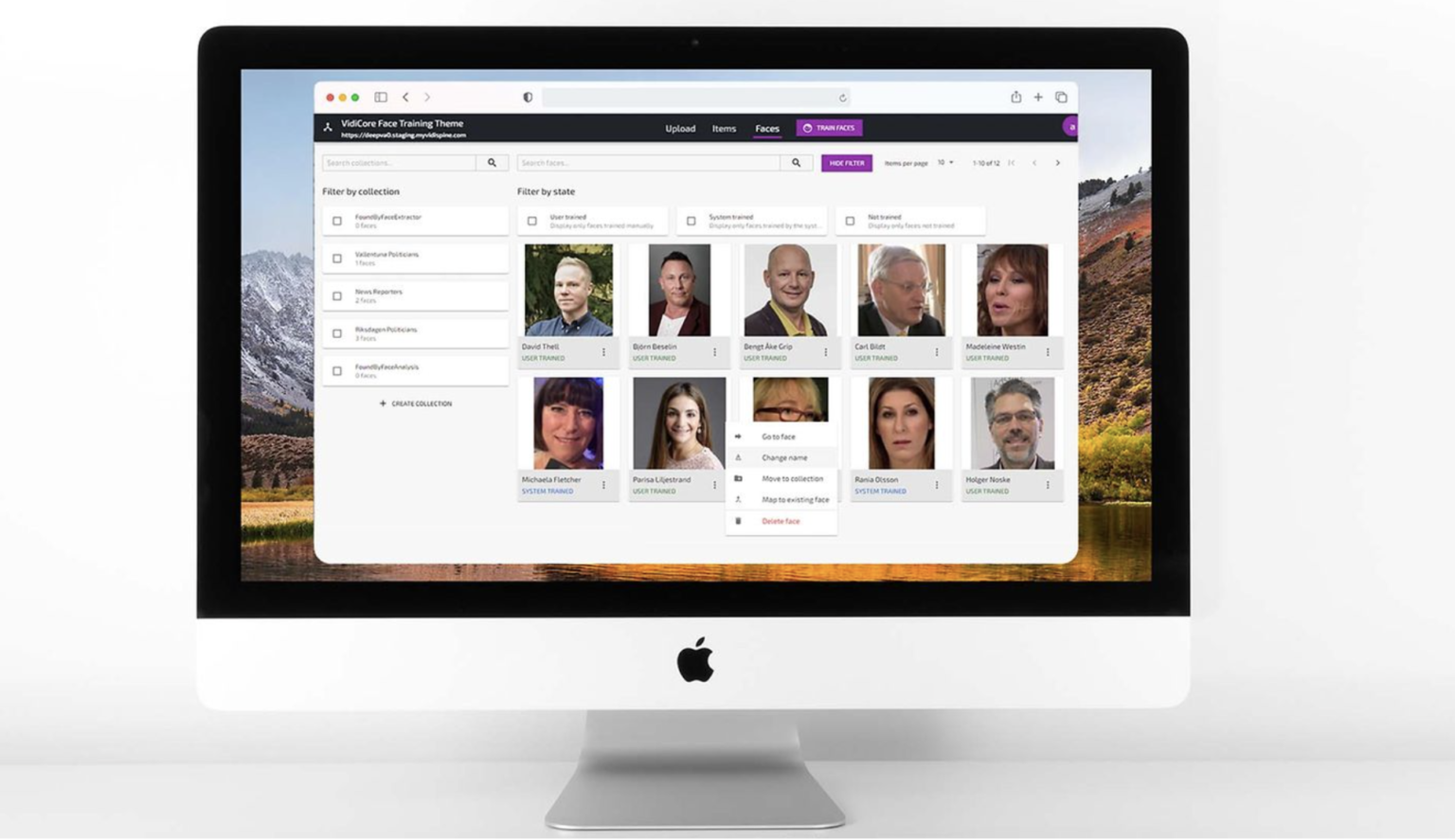
Vorteile der Integration von DeepVA ins MAM-System von Vidispine:
- Die Verwaltung und Nutzung von Trainingsdaten in der gewohnten MAM-Umgebung
- Intuitives User Interface mit integrierter Trainingsapplikation
- Trainingsklassen können ganz einfach in Datasets organisiert werden und mit einem Knopfdruck per API-Call trainiert werden
- Das trainierte KI-Modell steht nach wenigen Sekunden für die Analyse von Bildern und Videos zur Verfügung
- Analyse der Daten mit benutzerdefinierten Modellen auf Knopfdruck in der Benutzeroberfläche
- Timecode-akkurate Navigation im Videomaterial und somit bester Überblick über analysierte Objekte oder Gesichter
- Face Indexing: automatischer Erkennung von Gesichtern, die dem KI-Modell nicht bekannt sind werden mit Code versehen, manuell beschrieben und nachträglich im gesamten System automatisch beschrieben (Fingerprint)
- Die Integration von KI-Training in das bekannte MAM System ist ein entscheidender Schritt zur Verbesserung der Customer Experience
Woher kommen die Trainingsdaten?
Trainingsdaten können mit Hilfe der Face Dataset Creationextrahiert werden. Hierbei werden Trainingsdaten automatisch aus Videos und Livestreams extrahiert werden, indem im Bild eingefügte Namen mit den entsprechenden Gesichtern verknüpft und in einem Datensatz gespeichert werden. Trainingsdaten bieten so eine hohe Individualisierbarkeit und präzise und qualitative Analyse von visuellen Mediendaten. Das sogenannte Face Fingerprinting oder Face Indexing bietet die Möglichkeit nicht erkannte Gesichter mit einem bestimmten Index zu speichern, so dass sie später in Ihrer gesamten Datenbank markiert werden können. Sie werden einmal manuell benannt und automatisch auf alle auf die gleiche Weise erkannten Gesichter angewendet.
Zusammengefasst bietet die gemeinsame Lösung dem Nutzer im MAM-System eine Bandbreite von KI-Tools, die ihm zur Verfügung zu stehen, die sofort und ohne technisches Vorwissen angewendet werden können. Der Nutzer kann eigene, individualisierte KI-Modelle aufbauen und hat dabei mehrere Optionen des Trainings zur Hand. Die Anwendung dieser Modelle und die damit verbundene Analyse von Bild- und Videodateien sorgt für eine detailliertere und qualitativ hochwertigere Verschlagwortung und damit zu einer verbesserten Recherchierbarkeit der Mediendaten.






