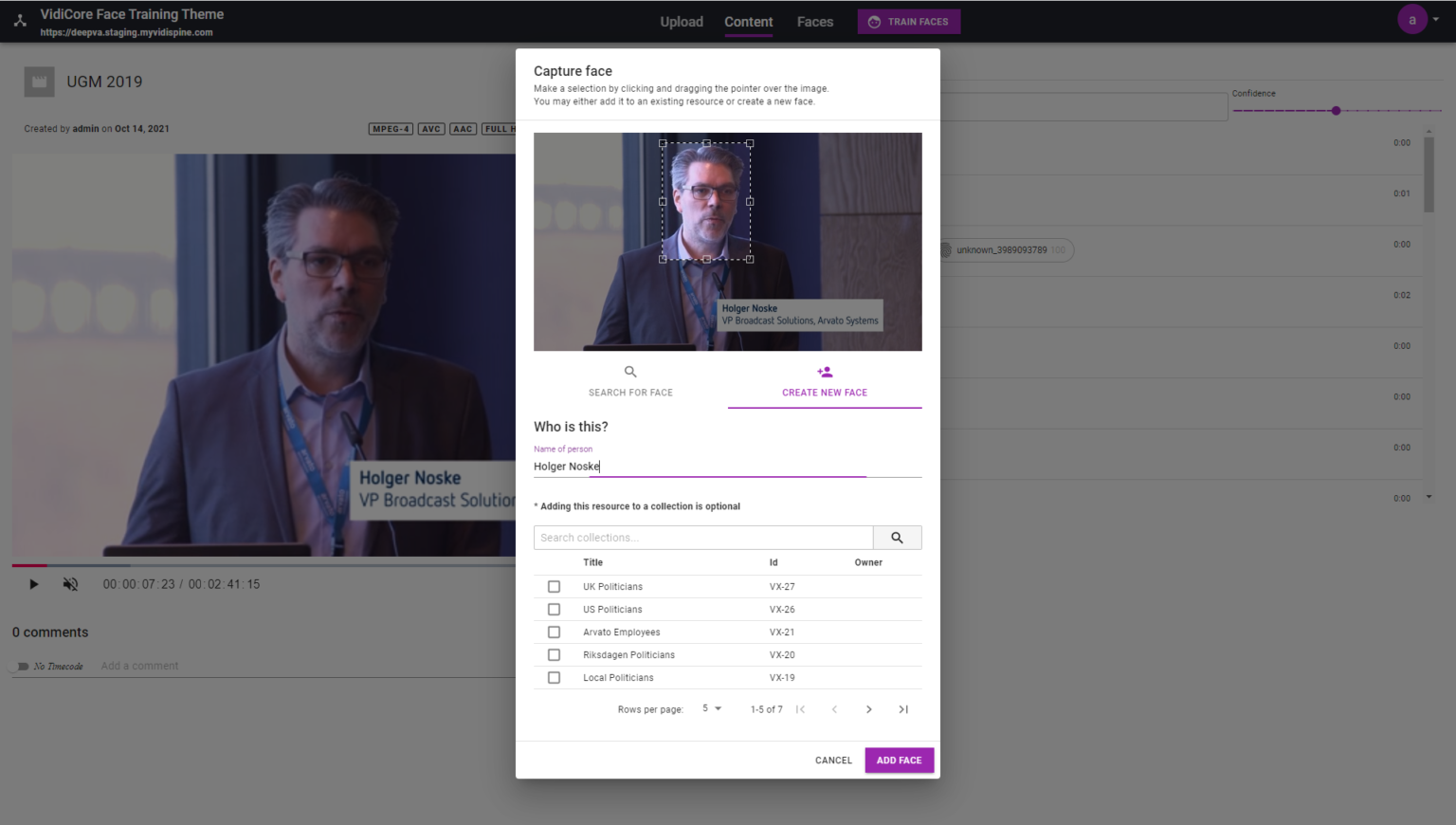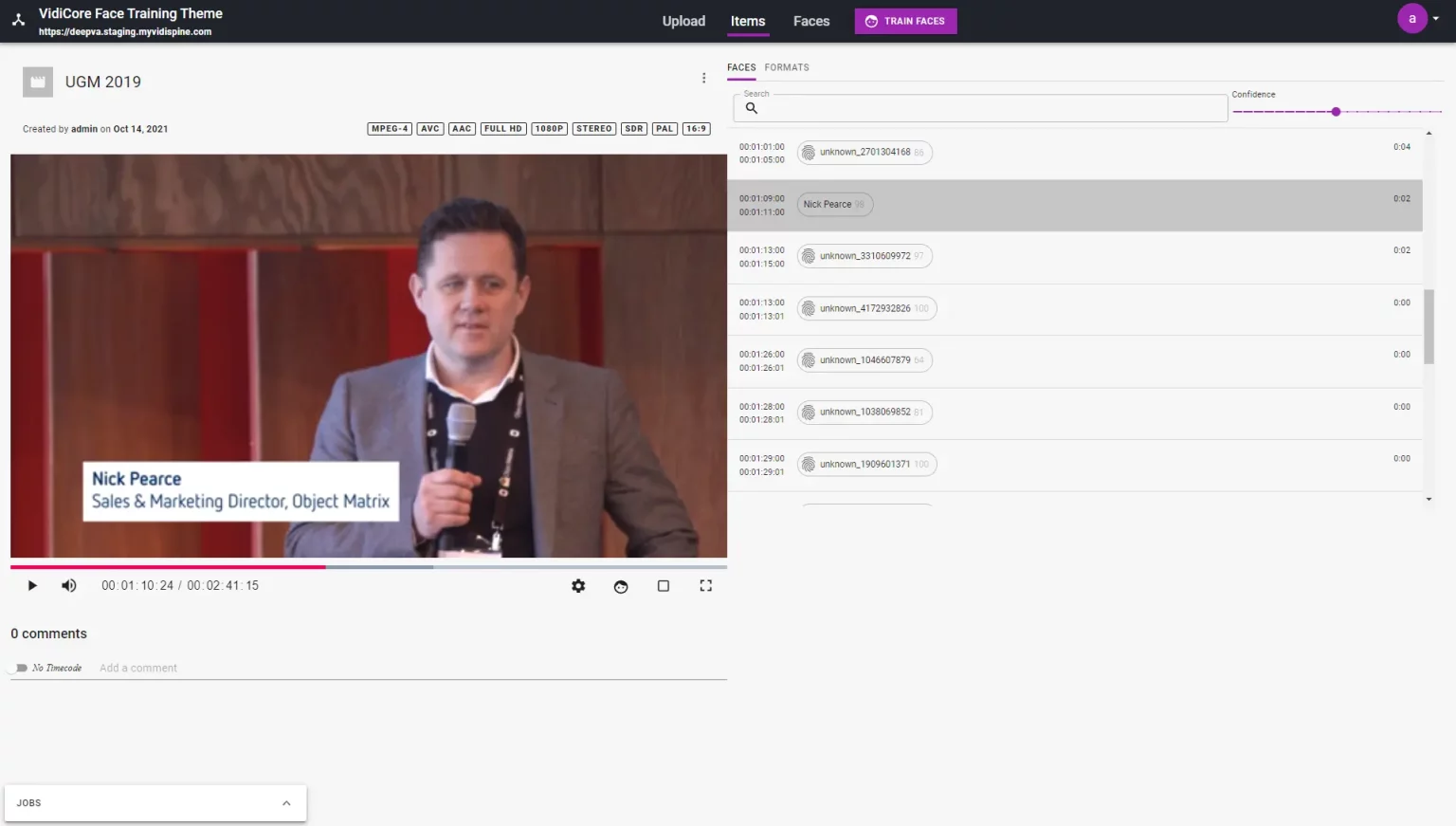

Our experience with generic AI solutions is that the required entities are often not identified in one's own content. Creating training data and managing datasets is complex and time-consuming. DeepVA's integration with our media service has shown us that customizable AI within the already familiar MAM interface can be intuitive and straightforward.

Ralf Jansen
Software Architect at Vidispine – An Arvato Systems Brand